
DeepSeek: The Enterprise AI Game-Changer You Cannot Afford to Ignore
Jan 29, 2025
NEWS

The release of DeepSeek-R1 represents more than just another large language model—it signals a turning point in how enterprises can approach AI adoption. As an open-source model rivaling proprietary giants like OpenAI, its technical and economic implications demand a closer look. For most enterprises, the path to AI adoption has been blocked by two towering barriers: prohibitive costs and vendor lock-in. DeepSeek emerges as a disruptive force.
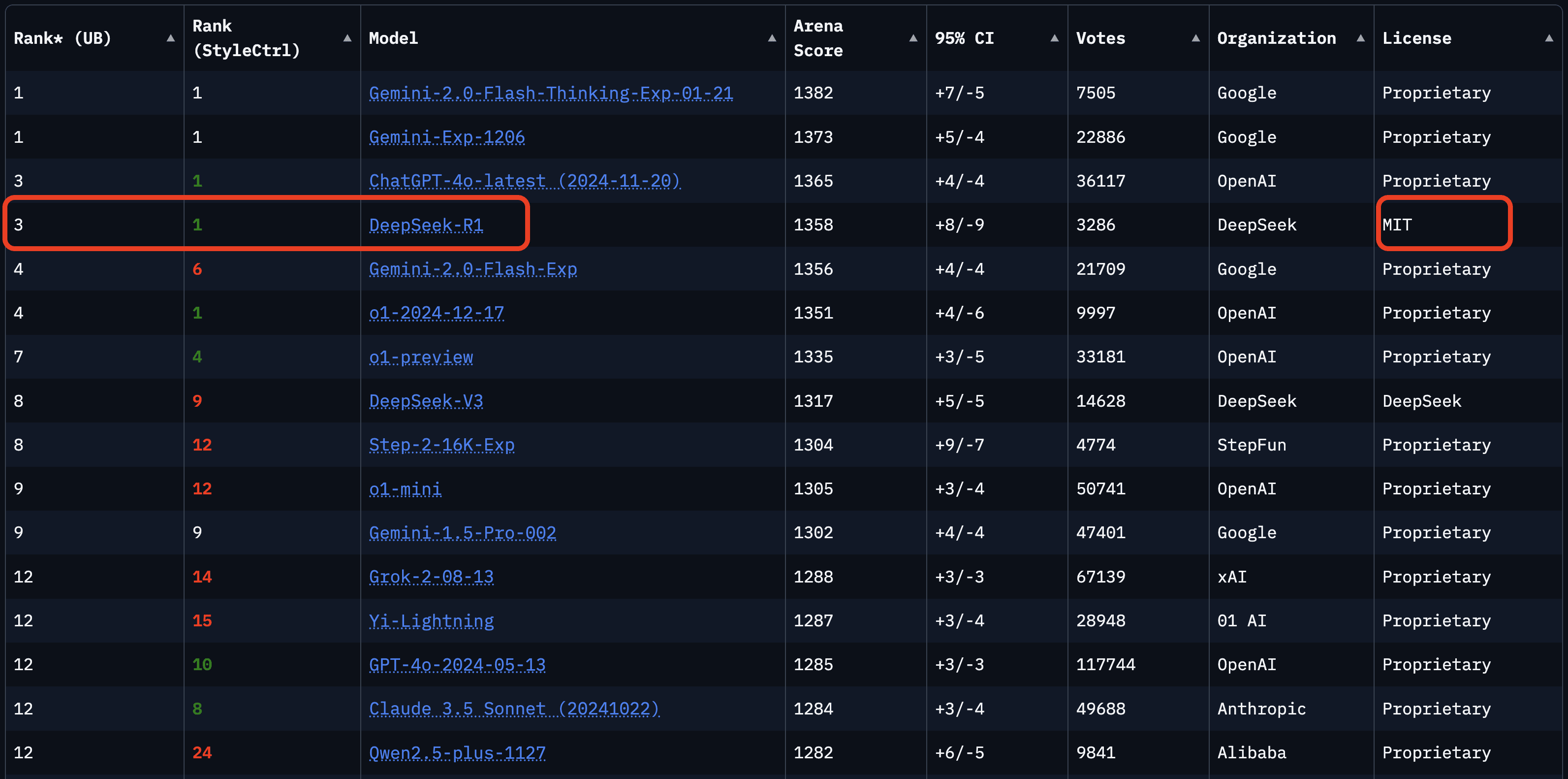
DeepSeek models have demonstrated strong performance on standard benchmarks, but its real-world utility is best illustrated by blind user comparisons. On leaderbpard platforms, where models are evaluated head-to-head using a Bradley-Terry model (similar to chess Elo ratings), DeepSeek models consistently rank among the top performers—often rivaling proprietary alternatives like OpenAI’s models.
General tasks in language domain as of Jan. 25, 2025:
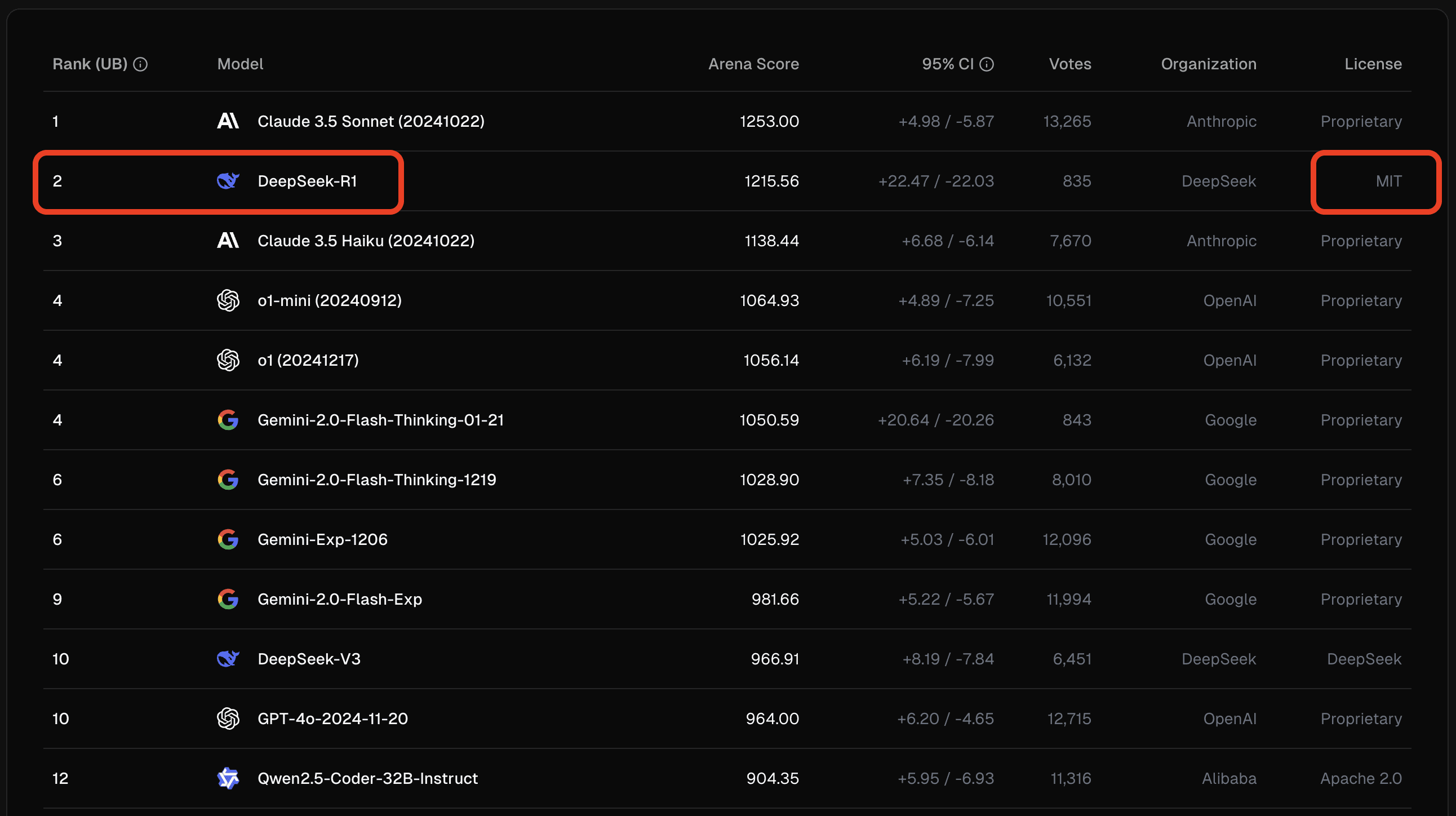
Web Development tasks leaderboard:
Now let’s dissect its relevance for businesses.
1. The Cost-Efficiency Breakthrough
Training at Scale Without Hundred-Million-Dollar Budgets
DeepSeek-R1 was trained for roughly $6M, a fraction of the costs associated with models like GPT-4. This challenges the narrative that cutting-edge AI requires hyperscale infrastructure—a point underscored by Meta’s recent $60B data center investments and Microsoft’s exploration of nuclear-powered compute.
Why this matters:
Smaller enterprises and industry-specific players can now realistically explore custom model training.
The $6M benchmark resets ROI expectations—projects once deemed “too niche” for AI may now be viable.
It signals that application-layer opportunities are intensifying: As foundation model providers compete on performance, businesses win through cheaper, more capable tools for building specialized applications. This shifts the battleground to implementation—where ROI is determined by how well models integrate with your workflows, data, and domain expertise (our consulting focus).
Inference Economics and Jevons Paradox
DeepSeek’s API pricing undercuts most proprietary models. If these costs hold, expect:
New use cases: Tasks like real-time document analysis or granular customer sentiment tracking become economically feasible.
Edge AI proliferation: Local deployment of smaller distilled models (e.g., 14B parameters on workstations) avoids cloud latency and fees.
If inference genuinely proves to be cheaper, we can expect an explosion of AI-driven applications, since higher ROI encourages businesses to expand their use of AI across more processes. To put into perspective, Project Stargate promised a $500B investment in AI infrastructure in the US. This investment will be ideal to run inference compute for increased use cases.
2. The Open-Source Advantage—And Its Caveats
As previously we have laid out, choosing between open-source and proprietary AI models is a crucial decision for business owners. Since most of DeepSeek models are open-source, a further discussion is provided here.
Control Over Compliance-Sensitive Workflows
Industries like healthcare, defence, finance, and governments often avoid cloud-based AI due to data residency rules. DeepSeek’s MIT license (open source and open weight) enables:
On-prem deployment: Process sensitive contracts, patient records, or financial data offline.
Transparency: Audit model behavior (unlike black-box APIs), critical for GDPR or HIPAA compliance.
But:
Hosting larger models (e.g., individual models or 671B-parameter Mixture-of-Experts) still requires significant in-house GPU resources.
The “open weights, closed data” problem persists—DeepSeek, to the best of our knowledge, hasn’t fully disclosed training datasets, limiting reproducibility. Fortunately, there are teams and companies trying to replicate it thanks to their academic papers and technical reports.
3. Transferable Technical Innovations Worth Understanding
This section touches on some technical details of their models. This section is for AI/ML practitioners and some understanding of the field is necessary. Otherwise, feel free to skip this section.
What’s New (and What’s Not)
Some techniques used in this model—such as Mixture of Experts (MoE), distillation, and Chain of Thought reasoning—are not new. However, the key innovations in the paper introduce notable differences that can be applied to other AI initiatives:
Simplicity & Scale as Key Factors: Akin to Rich Sutton’s bitter lesson, emphasizing on simpler solutions that scale better often lead to superior performance.
Iterative Data Collection: A novel approach to refining datasets over multiple iterations. It starts from a small seed dataset but it grows into larger datasets in each iteration without losing relevancy to the task.
Better RL Techniques: They apply large-scale reinforcement learning (RL) without supervised fine-tuning (SFT). Their training algorithm, GRPO (Generalized Reward Policy Optimization), is built on top of the previous methods: REINFORCE → TRPO → PPO → GRPO.
These insights extend beyond this specific model and offer valuable takeaways for applying AI advancements in other enterprise settings.
Escaping LLM Plateau?
In a recent post we elaborated on why we need new breakthroughs to escape the plateau that foundation models are about to hit. In their paper they say the following that seems to hint at similar shortcomings even with this better RL technique:
RL enhances Maj@K’s performance but not Pass@K. These findings indicate that RL enhances the model’s overall performance by rendering the output distribution more robust, in other words, it seems that the improvement is attributed to boosting the correct response from TopK rather than the enhancement of fundamental capabilities.
In other words, RL refines the base model’s existing knowledge (making correct answers more consistently appear in TopK outputs) but doesn’t expand its fundamental capabilities. This suggests current RL methods optimize what’s already present rather than breaking new ground. So, the search for a method to escape the plateau has to continue.
4. Strategic Implications for Enterprises
Better, cheaper models mean wider ROI potential—across many departments. Some notable use cases are as follows:
Document Analysis & Compliance
Legal Teams can rapidly parse lengthy contracts or regulation documents without fear of data leakage.
Finance Departments can monitor and flag suspicious activity in massive logs.
2. Customer Support & Sales
Chatbots with advanced reasoning can handle complex queries at scale.
Personalized sales scripts or product recommendations with minimal overhead.
3. Code Generation & QA
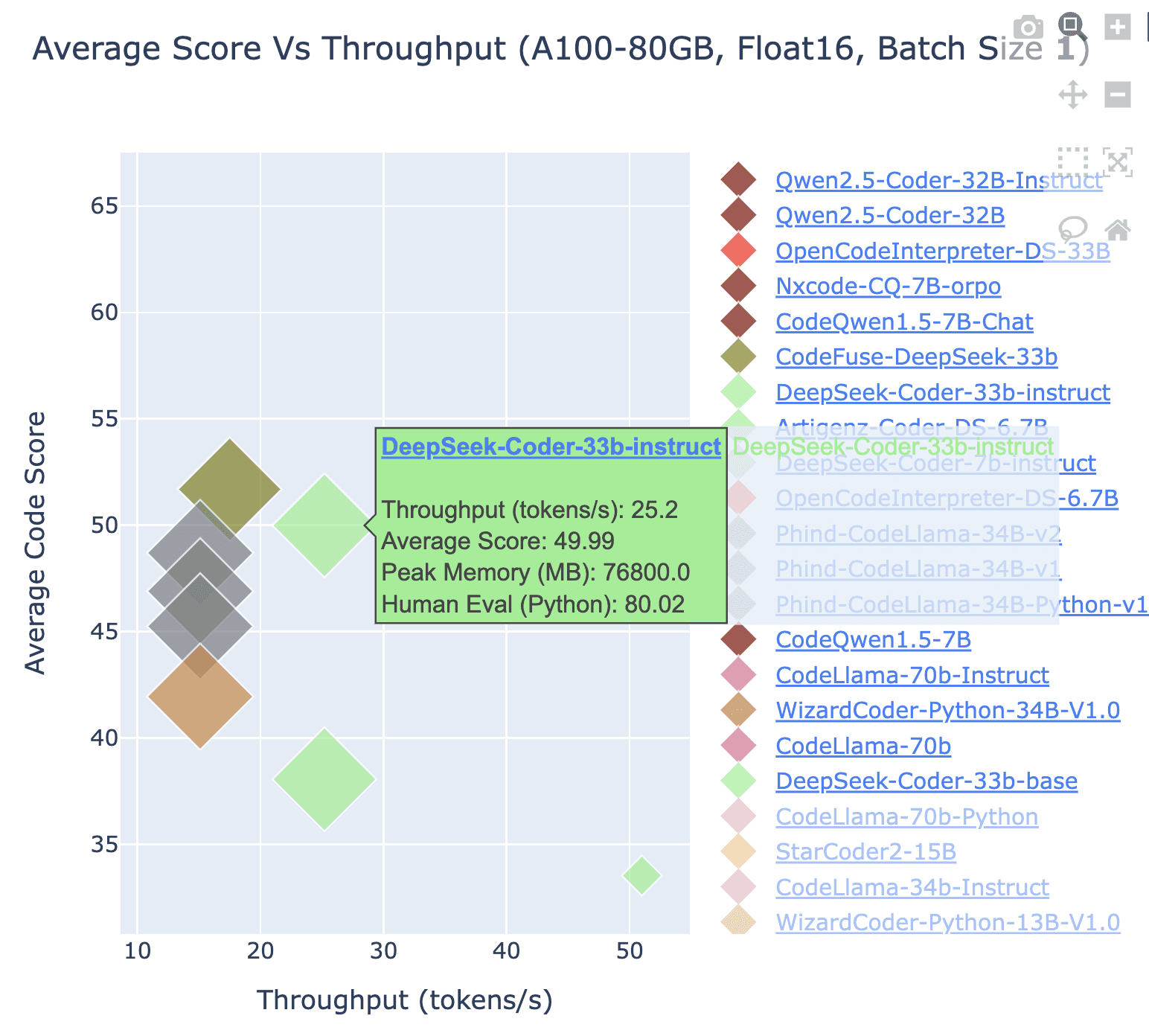
Developers can use the model to generate test cases or suggest code improvements, accelerating software timelines. Following plot shows average code score vs throughput of DeepSeek Coder model compared to similar open-source ones.
5. Limitations and Unanswered Questions
This is a rapidly evolving space, and our analysis is based on the information available at the time of writing. As with any new development, there are important caveats and open questions to consider. Ultimately, time will reveal how these factors play out.
Reproducibility Concerns
While the technical report details RL strategies, replicating DeepSeek’s $6M training run remains challenging for most. Some key unknowns:
Exact data mix and cleaning pipelines.
Infrastructure efficiency tricks (model parallelism, caching).
The Cost Mirage?
Is DeepSeek’s pricing sustainable, or a loss leader to attract enterprise clients? Watch for:
Hidden fees for high-throughput workloads.
Long-term API uptime compared to OpenAI/AWS.
Key Takeaways for Businesses
Experiment locally first: Test distilled models for internal workflows before cloud commits. “Smaller” 14B models can be experimented on a decent workstation or laptop. Note that getting started with 1,000 requests per day for free on the HuggingFace Inference API is as easy as following:
Audit compliance needs: On-prem vs. API trade-offs vary by industry.
Focus on integration layers: Fine-tuning and guardrails will determine ROI more than raw model performance.
DeepSeek-R1 isn’t a magic bullet—but it does expand what’s possible for enterprises willing to navigate the open-source ecosystem.
Need an Objective Assessment?
We help businesses cut through the hype. Let’s map AI’s capabilities to your specific needs:
Cost-benefit analysis: On-prem vs. API deployment.
Proof-of-concept design: Validate performance on your tasks.
Long-term strategy: Balancing open-source flexibility with vendor support.
